Follow nofollow, index noindex: questo è il dilemma!
Scopriamo perché il Meta Tag Robots è un piccolo supereroe che ci permette di indicizzare in modo corretto un sito web.
Hai scelto di realizzare il tuo sito in WordPress e finalmente è pronto.
Hai scritto i tuoi fantastici contenuti in ottica SEO, title, description, meta description, keywords, è tutto in ordine.
Anche Yoast ti dà l’agognato semaforo verde, le immagini hanno descrizioni e tag alt, non ti resta che andare online.
Poi si attiva una sirena nella tua testa che non ti dà tregua “follow nofollow, index noindex”, e non puoi fare altro che controllare se ad ogni singolo contenuto siano state assegnate le giuste istruzioni.
Non c’è alcun dubbio che un contenuto originale, di valore e pertinente è alla base di un buon posizionamento, ma il primo passo da fare è indicizzare il sito web, ossia fare in modo che sia presente negli indici dei database dei motori di ricerca.
Quindi coraggio, affrontiamo uno dei freddi aspetti tecnici che permettono ai motori di ricerca di sapere che il tuo sito esiste.
Ci sono infatti delle azioni che è necessario fare per promuovere un sito e farlo conoscere nell’infinito universo del Web. È proprio ora che entra in scena il Meta Tag Robots che fornisce informazioni aggiuntive sui contenuti della pagina e indica allo spider il comportamento da assumere in fase di visita e analisi della stessa, permette di dare istruzioni ai bot per ogni singola pagina in cui è presente, non al sito web nel suo complesso, per questo esiste il file robots.txt. Questo file si trova nella root principale del tuo sito web e ha la funzione di bloccare la scansione di determinate pagine da parte del motore di ricerca e segue il protocollo REP (Robots Exclusion Protocol). In questo file è possibile applicare delle restrizioni all'interno del sito web utilizzando le seguenti regole:
Disallow: per escludere l’indicizzazione su una directory o su una singola pagina
Allow: per permettere l’analisi della pagina
Inoltre bisogna ricordarsi che se si elimina un url dalla sitemap il bot continuerà a trovare l’indirizzo a meno che non venga rimosso dal file robots.txt scrivendo: Disallow:/url-da-rimuovere/.
Cosa sono e cosa significano: index, noindex, follow nofollow?
Si tratta di attributi da assegnare a un contenuto e che definiscono l’istruzione allo spider relativo alla pagina. Nello specifico:
- index – comunica al robot del motore di ricerca che è possibile indicizzare la pagina, consentendogli di inserirla nel suo database
<meta name="robots" content="index">
- noindex – comunica al robot del motore di ricerca che la pagina non va indicizzata, quindi non apparirà nei motori di ricerca e non sarà salvata nei loro database
<meta name="robots" content="noindex">
- follow – questo tag serve a indicare al motore che il robot deve seguire i link della pagina per indicizzare anche quelle successive
<meta name="robots" content="follow">
- nofollow – questo tag invece serve per indicare al motore di ricerca di non seguire i link che da quella pagina puntano verso altre pagine
<meta name="robots" content="nofollow">
Il meta name “robots” rappresenta un’assegnazione generica, indica che l’istruzione si applica a tutti i crawler, non solo ad esempio a quello di Google. Se si volesse sottoporre solo a Google la scansione di una pagina del nostro sito, basterà scrivere la seguente istruzione:
<meta name="googlebot" content="index">
Come si usano?
Usarli è semplice, se il codice non rappresenta fonte di terrore e raccapriccio, possono essere facilmente inseriti manualmente tra i tag <head> e </head>, ma se si usa il plugin Yoast basterà selezionare gli attributi e lui scriverà il codice al posto nostro.
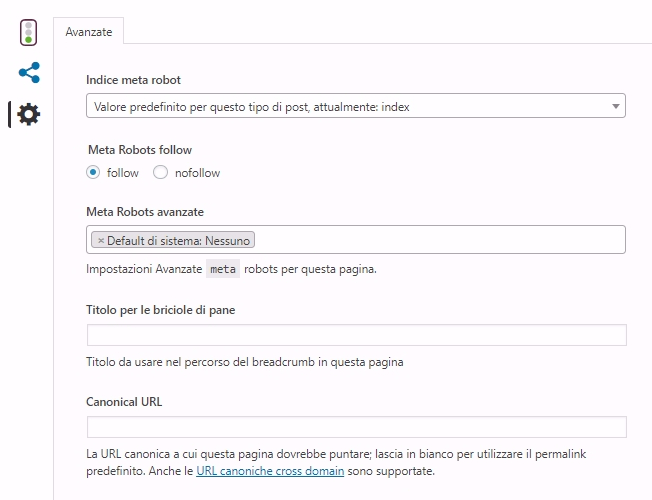
Perché si usano?
È noto che il posizionamento sui motori di ricerca dipende anche dalla link popularity del nostro fantastico sito cioè dalla quantità e, soprattutto, dalla qualità di backlink. In assenza di istruzioni robots tutti gli spider tenderanno a indicizzare le pagine che incontrano e a seguire i link, buoni o cattivi senza alcuna distinzione e proprio qui entriamo in gioco noi!
Prendiamo ad esempio l’attributo “nofollow”, perché mai dovremmo suggerire ai bot di non seguire un link?
Molto semplice, se ad esempio abbiamo attivato l’area di commenti a un articolo, può succedere che degli utenti furbetti più che un commento inseriscano un link al loro sito, che però non ha alcuna pertinenza con gli argomenti di cui trattiamo. Il loro scopo è solo di aumentare la loro link popularity, in questo modo il nostro sito perde di credibilità agli occhi vigili dell’implacabile Pinguino di Google. Si tratta di Penguin: il terribile algoritmo che penalizza i siti che utilizzano tecniche di link building ingannevoli per migliorare il loro posizionamento.
Bene, con questa istruzione indichiamo al motore di ricerca che non riconosciamo il sito a cui la pagina linka, e che non abbiamo alcuna intenzione di passare valore a quella pagina.
Poi può capitare di avere contenuti duplicati, o semplicemente si preferisce non mostrare una pagina al motore di ricerca, per motivi di sicurezza o di privacy, perché contiene informazioni riservate come password o statistiche. Niente paura, abbiamo a nostra disposizione l’attributo “noindex” grazie al quale quella specifica pagina non sarà più presente nel database del search engine.
Una volta date le giuste istruzioni siamo pronti a estrarre la sitemap generata da Yoast e inserirla nella Google Search Console, in modo che il motore di ricerca possa iniziare l’analisi del sito.
Avete indicizzato il vostro sito ma ancora non riuscite a trovarvi (mica vi sentite persi però)?
È normalissimo, perché il posizionamento è un’altra storia… quindi #staytuned, seguirà un altro aggiornamento con tutte le informazioni sulla SERP di Google e quelle che possono sembrare delle magie che avvengono senza che ce ne accorgiamo!