Salve a tutti, H4ck3rM4n dopo un piccolo periodo di assenza è tornato, e con questo breve e semplice articolo.
Un buon sviluppatore web si occupa molto spesso di scrivere il codice sorgente per applicazioni/browser oppure di controllare e di testare porzioni di codice Javascript al fine di ottimizzare la User Experience (conosciuto con l’acronimo di UX) delle pagine di un sito.
Ma bisogna fare attenzione al codice JS che implementiamo nel nostro progetto, perché a volte per abbellire la UX e renderla più fruibile al pubblico, potremmo avere dei problemi relativi alla scansione delle pagine web da parte di Google, che (suo malgrado) non riuscirebbe a vedere tutti gli elementi della struttura delle pagine e quindi non riuscirebbe ad indicizzarle in modo corretto.
Come è possibile ciò? Lo scopriamo subito.
Javascript e il controllo degli elementi di una pagina attraverso i DOM
Javascript per utilizzare elementi HTML, al fine di rendere una pagina web fruibile per l’utente, si avvale dei DOM (Document Object Model) che non sono altro che dei modelli di oggetti in grado di “agganciarsi” agli elementi della struttura HTML ed interagire con essi.
Google attraverso il crawler scansiona il codice JS e cerca di capirne la vera natura e i vari utilizzi del codice. Ed è proprio qui che sorge il problema. Per comprendere bene tutto questo vi faccio un esempio:
Prendiamo una piattaforma di blogging che abbia utilizzato del codice JS per nascondere dei paragrafi all’apertura della pagina web, il crawler di Google scansiona la pagina e cerca di estrarre URL utilizzando il suo parser.
Il problema sta nel fatto che eseguendo il codice JS richiamato all’interno della pagina (quello che nasconde i paragrafi), Google non riesce a mettere a fuoco il testo delle pagine, causando una grossa penalizzazione e togliendo, di conseguenza, l'indicizzazione della pagina scansionata.
Tuttavia, il crawler scansiona ed estrae tutti gli url collegati all’interno della pagina Web presenti nel tag <a href="URL"> senza verificare ed eseguire il codice JavaScript.
E allora come fa il signor Google ad eseguire il codice sorgente JavaScript ed accorgersi che qualcosa non va?
Big G non ha solo i crawler e gli spider per poter scansionare le pagine web ma c'è una grossa infrastruttura piena di algoritmi complessi, processi e sottoprocessi che ne determinano ed influenzano la SEO e la ricerca nella SERP.
Questa infrastruttura prende nome di Caffeine, e i crawler ne sono parte integrante.
Il Web Rendering Service
Il componente principale che processa ed esegue il codice JavaScript al momento dell’indicizzazione della pagina è un componente di Caffeine, chiamato Web Rendering Service (WRS).
Il WRS e i crawlers fanno un vero e proprio lavoro di squadra: i crawlers indicizzano la pagina web e inviano l’URL canonico al WRS che andrà a processarlo. Così facendo è possibile eseguire e renderizzare il codice Js, senza escludere gli elementi strutturali HTML.
Per capire meglio il funzionamento, aprite Search Console di Google, andate su “altre risorse” e cliccate sulla voce PageSpeed Insight (beh questo è il nuovo tool e algoritmo di Google), inserite il vostro sito e cliccate su analizza.
Nello spazio a destra verrà visualizzato il vostro sito rispetto all’UI Desktop o Mobile mentre, nella parte a sinistra verranno visualizzati le possibili ottimizzazioni di codice html, Js e contenuti grafici, che si dovranno fare affinché si rispetti il nuovo algoritmo (in fondo alla pagina c’è l’opportunità di scaricare i codici ottimizzati ma non ditelo agli sviluppatori :D) . Google non è certamente StackOverFlow ma è in grado di fornire soluzioni utili per quelli che sono i suoi major update in fatto di indicizzazione ☺.
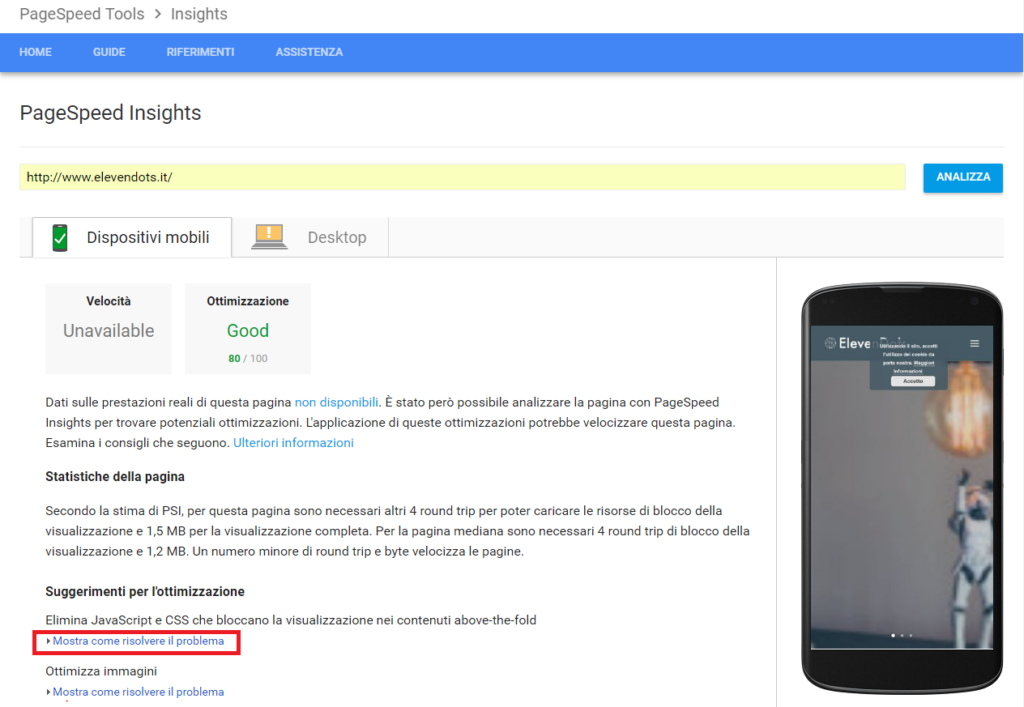
Le cose però si complicano quando si utilizzano i vari framework che si trovano in rete, come Angular JS, React Js o altri framework JavaScript. Queste piattaforme facilitano sì allo sviluppatore la creazione di SPA (Single-Page Applications), tuttavia del loro utilizzo ne risente maggiormente il WRS, dato che molti framework sfruttano sia gli elementi DOM che gli attributi HTML, aumentando la difficoltà ai crawlers di leggere il contenuto della pagina web.
Cosa possiamo fare allora per migliorare i rapporti tra SEO e JS?
Google non sconsiglia l’uso di questi Framework JavaScript nelle pagine, ma per fare un buon lavoro SEO, è cosa buona e giusta limitarne l’uso.
Per esempio, se stiamo sviluppando un blog sarebbe poco utile utilizzare un Framework JavaScript, dato che il loro uso è più adatto in campi più complessi quali Web app per smartphone, e non di certo per un blog dove il compito principale è fruire di contenuti testuali.
Queste sono alcune raccomandazioni:
- Impiega i framework per facilitare compiti più complessi come i Single-Page Application.
- Fai una breve ricerca sui framework da utilizzare per migliorare la SEO e far combaciare la UI (dato che questi problemi nascono da script che nascondono elementi senza mai essere utilizzati dall’utente, ma risultano comunque in pagina).
- Per l’utente meno esperto che usa WordPress consiglio di utilizzare plugin a pagamento come la versione Pro di Yoast!
- Per i programmatori più esperti invece consiglio assolutamente i nuovi tag HTML5 per formattare e rendere più fruibile il contenuto sul web. Caffeine tiene conto anche di questo attraverso il parser dei crawlers. Vi riporto il link per la lista completa dei tag HTML5 che trovate qui
Per oggi vi saluto, ma posso già spoilerare che tra qualche settimana arriverà il mio nuovo articolo della saga “Creare un template per WordPress”!
Stay tuned 😉